The governance of Britain and the governance of the Internet have this in common: the ultimate authority in both cases is to a large extent a “gentleman’s agreement”. For the same reason: both were devised by a relatively small, homogeneous group of people who trusted each other. In the case of Britain, inertia means that even without a written constitution the country goes on electing governments and passing laws as if.
Most people have no reason to know that the Internet’s technical underpinnings are defined by a series of documents known as RFCs, for Requests(s) for Comments. RFC1 was defined in April 1969; the most recent, RFC9598, is dated just last month. While the Internet Engineering Task Force oversees RFCs’ development and administration, it has no power to force anyone to adopt them. Throughout, RFC standards have been created collaboratively by volunteers and adopted on merit.
A fair number of RFCs promote good “Internet citizenship”. There are, for example, email addresses (chiefly, webmaster and postmaster) that anyone running a website is supposed to maintain in order to make it easy for a third party to report problems. Today, probably millions of website owners don’t even know this expectation exists. For Internet curmudgeons over a certain age, however, seeing email to those addresses bounce is frustrating.
Still, many of these good-citizen practices persist. One such is the Robots Exclusion Protocol, updated in 2022 as RFC 9309, which defines a file, “robots.txt”, that website owners can put in place to tell automated web crawlers which parts of the site they may access and copy. This may have mattered less in recent years than it did in 1994, when it was devised. As David Pierce recounts at The Verge, at that time an explosion of new bots were beginning to crawl the web to build directories and indexes (no Google until 1998!). Many of those early websites were hosted on very small systems based in people’s homes or small businesses, and could be overwhelmed by unrestrained crawlers. Robots txt, devised by a small group of administrators and developers, managed this problem.
Even without a legal requirement to adopt it, early Internet companies largely saw being good Internet citizens as benefiting them. They, too, were small at the time, and needed good will to bring them the users and customers that have since made them into giants. It served everyone’s interests to comply.
Until more or less now. This week, Katie Paul is reporting at Reuters that “AI” companies are blowing up this arrangement by ignoring robots.txt and scraping whatever they want. This news follows reporting by Randall Lane at Forbes that Perplexity.ai is using its software to generate stories and podcasts using news sites’ work without credit. At Wired, Druv Mehrotra and Tim Marchman report a similar story: Perplexity is ignoring robots.txt and scraping areas of sites that owners want left alone. At 404 Media, Emmanuel Maiberg reports that Perplexity also has a dubious history of using fake accounts to scrape Twitter data.
Let’s not just pick on Perplexity; this is the latest in a growing trend. Previously, hiQ Labs tried scraping data from LinkedIn in order to build services to sell employers, the courts finally ruled in 2019 that hiQ violated LinkedIn’s terms and conditions. More controversially, in the last few years Clearview AI has been responding to widespread criticism by claiming that any photograph published on the Internet is “public” and therefore within its rights to grab for its database and use to identify individuals online and offline. The result has been myriad legal actions under data protection law in the EU and UK, and, in the US, a sheaf of lawsuits. Last week, Kashmir Hill reported at the New York Times, that because Clearview lacks the funds to settle a class action lawsuit it has offered a 23% stake to Americans whose faces are in its database.
As Pierce (The Verge) writes, robots.txt used to represent a fair-enough trade: website owners got search engine visibility in return for their data, and the owners of the crawlers got the data but in return sent traffic.
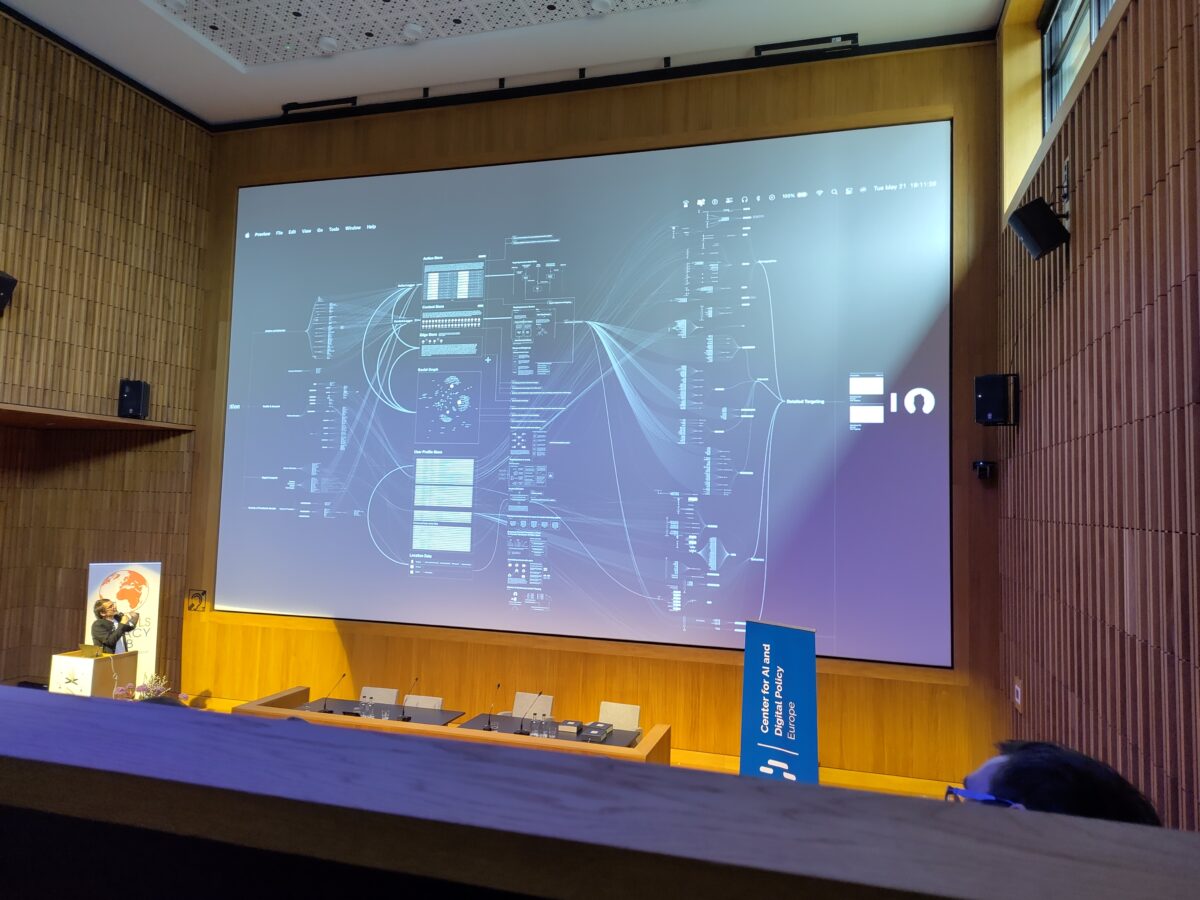
But AI startups ingesting data to build models don’t offer any benefit in return. Where search engines have traditionally helped people find things on other sites, the owners of AI chatbots want to keep the traffic for themselves. Perplexity bills itself as an “answer engine”. A second key difference is this: none of these businesses are small. As Vladen Joler pointed out last month at CPDP, “AI comes pre-monopolized.” Getting into this area requires billions in funding; by contrast many early Internet businesses started with just a few hundred dollars.
This all feels like a watershed moment for the Internet. For most of its history, as Charles Arthur writes at The Overspill, every advance has exposed another area where the Internet operates on the basis of good faith. Typically, the result is some form of closure – spam, for example, led the operators of mail servers to close to all but authenticated users. It’s not clear to a non-technical person what stronger measure other than copyright law could replace the genteel agreement of robots.txt, but the alternative will likely be closing open access to large parts of the web – a loss to all of us.
Illustrations: Vladen Joler at CPDP 2024, showing his map of the extractive industries required to underpin “AI”.
Wendy M. Grossman is the 2013 winner of the Enigma Award. Her Web site has an extensive archive of her books, articles, and music, and an archive of earlier columns in this series. She is a contributing editor for the Plutopia News Network podcast. Follow on Mastodon.