So this week I had to provide a new password for an online banking account. This is always fraught, even if you use a password manager. Half the time whatever you pick fails the site’s (often hidden) requirements – you didn’t stand on your head and spit a nickel, or they don’t allow llamas, or some other damn thing. This time, the specified failures startled me: it was too long, and special characters and spaces were not allowed. This is their *new* site, created in 2022.
They would have done well to wait for the just-released proposed password guidelines from the US National Institute for Standards and Technology. Most of these rules should have been standard long ago – like only requiring users to change passwords if there’s a breach. We can, however, hope they will be adopted now and set a consistent standard. To date, the fact that everyone has a different set of restrictions means that no secure strategy is universally valid – neither the strong passwords software generates nor the three random words the UK’s National Cyber Security Centre has long recommended.
The banking site we began with fails at least four of the nine proposed new rules: the minimum password length (six) is too short – it should be eight, preferably 15; all Unicode characters and printing ASCII characters should be acceptable, including spaces; maximum length should be at least 64 characters (the site says 16); there should be no composition rules mandating upper and lower case, numerals, and so on (which the site does). At least the site’s rules mean it won’t invisibly truncate the password so it’s impossible to guess how much of it has actually been recorded. On the plus side, a little surprisingly, the site did require me to choose my own password hint question. The fact that most sites use the same limited set of questions opens the way for reused answers across the web, effectively undoing the good of not reusing passwords in the first place.
This is another of those cases where the future was better in the past: for at least 20 years passwords have been about to be superseded by…something – smart cards, dongles, biometrics, picklists and typing patterns, images, lately, passkeys and authenticator apps. All have problems limiting their reach. Single signons are still offered by Facebook, Google, and others, but the privacy risks are (I hope) widely understood. The “this is the next password” crowd have always underestimated the complexity of replacing deeply embedded habits. We all hate passwords – but they are simple to understand and work across multiple devices. And we’re used to them. Encryption didn’t succeed with mainstream users until it became invisibly embedded inside popular services. I’ll guess that password replacements will only succeed if they are similarly invisible. Most are too complicated.
In all these years, despite some improvements, passwords have only gotten more frustrating. Most rules are still devised with desktop/laptop computers in mind – and yield passwords that are impossible to type on phones. No one takes a broad view of the many contexts in which we might have to enter passwords. Outmoded threat models are everywhere. Decades after the cybercafe era, sites, operating systems, and other software all still code as if shoulder surfing were still an important threat model. So we end up with sillinesses like struggling to type masked wifi passwords while sitting in coffee shops where they’re prominently displayed, and masks for one-time codes sent for two-factor authentication. So you fire up a text editor to check your typing and then copy and paste…
Meanwhile, the number of passwords we have to manage continues to escalate. In a recent extended Mastodon thread, digital services expert Jonathan Kamens documented his adventures updating the email addresses attached to 1,200-plus accounts. He explained: using a password manager makes it easy to create and forget new accounts by the hundred.
In a 2017 presentation, Columbia professor Steve Bellovin provides a rethink of all this, much of it drawn from his his 2016 book Thinking Security. Most of what we think we know about good password security, he argues, is based on outmoded threat models and assumptions – outmoded because the computing world has changed, but also because attackers have adapted to those security practices. Even the focus on creating *strong* passwords is outdated: password strength is entirely irrelevant to modern phishing attacks, to compromised servers and client hosts, and to attackers who can intercept communications or control a machine at either end (for example, via a keylogger). A lot depends if you’re a high-risk individual likely to be targeted personally by a well-resourced attacker, a political target, or, like most of us, a random target for ordinary criminals.
The most important thing, Bellovin says, is not to reuse passwords, so that if a site is cracked the damage is contained to that one site. Securing the email address used to reset passwords is also crucial. To that end, it can be helpful to use a separate and unpublished email address for the most sensitive sites and services – anything to do with money or health, for example.
So NIST’s new rules make some real sense, and if organizations can be persuaded to adopt them consistently all our lives might be a little bit less fraught. NIST is accepting comments through October 7.
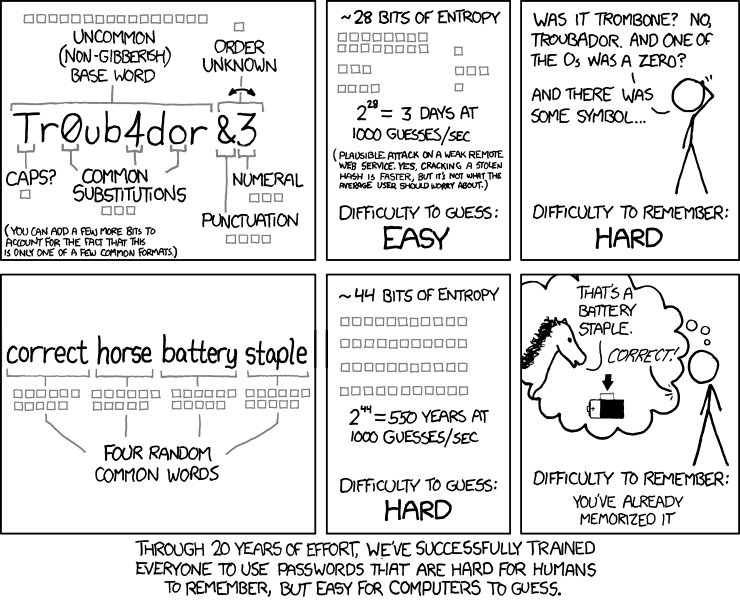
Illustrations: XKCD on password strength.
Wendy M. Grossman is the 2013 winner of the Enigma Award. Her Web site has an extensive archive of her books, articles, and music, and an archive of earlier columns in this series. She is a contributing editor for the Plutopia News Network podcast. Follow on Mastodon.






.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}