In one sense, the EU’s barely dry AI Act and the other complex legislation – the Digital Markets Act, Digital Services Act, GDPR, and so on -= is a triumph. Flawed it may be, but it’s a genuine attempt to protect citizens’ human rights against a technology that is being birthed with numerous trigger warnings. The AI-with-everything program at this year’s Computers, Privacy, and Data Protection, reflected that sense of accomplishment – but also the frustration that comes with knowing that all legislation is flawed, all technology companies try to game the system, and gaps will widen.
CPDP has had these moments before: new legislation always comes with a large dollop of frustration over the opportunities that were missed and the knowledge that newer technologies are already rushing forwards. AI, and the AI Act, more or less swallowed this year’s conference as people considered what it says, how it will play internationally, and the necessary details of implementation and enforcement. Two years at this event, inadequate enforcement of GDPR was a big topic.
The most interesting future gaps that emerged this year: monopoly power, quantum sensing, and spatial computing.
For at least 20 years we’ve been hearing about quantum computing’s potential threat to public key encryption – that day of doom has been ten years away as long as I can remember, just as the Singularity is always 30 years away. In the panel on quantum sensing, Chris Hoofnagle argued that, as he and Simson Garfinkel recently wrote at Lawfare and in their new book, quantum cryptanalysis is overhyped as a threat (although there are many opportunities for quantum computing in chemistry and materials science). However, quantum sensing is here now, works (because qubits are fragile), and is cheap. There is plenty of privacy threat here to go around: quantum sensing will benefit entirely different classes of intelligence, particularly remote, undetectable surveillance.
Hoofnagle and Garfinkel are calling this MASINT, for machine and signature intelligence, and believe that it will become very difficult to hide things, even at a national level. In Hoofnagle’s example, a quantum sensor-equipped drone could fly over the homes of parolees to scan for guns.
Quantum sensing and spatial computing have this in common: they both enable unprecedented passive data collection. VR headsets, for example, collect all sorts of biomechanical data that can be mined more easily for personal information than people expect.
Barring change, all that data will be collected by today’s already-powerful entities.
The deeper level on which all this legislation fails particularly exercised Cristina Caffarra, the co-founder of the Centre for Economic Policy Research in the panel on AI and monopoly, saying that all this legislation is basically nibbling around the edges because they do not touch the real, fundamental problem of the power being amassed by the handful of companies who own the infrastructure.
“It’s economics 101. You can have as much downstream competition as you like but you will never disperse the power upstream.” The reports and other material generated by government agencies like the UK’s Competition and Markets Authority are, she says, just “admiring the problem”.
A day earlier, the Novi Sad professor Vladen Joler had already pointed out the fundamental problem: at the dawn of the Internet anyone could start with nothing and build something; what we’re calling “AI” requires billions in investment, so comes pre-monopolized. Many people dismiss Europe for not having its own homegrown Big Tech, but that overlooks open technologies: the Raspberry Pi, Linux, and the web itself, which all have European origins.
In 2010, the now-departing MP Robert Halfon (Con-Harlow) said at an event on reining in technology companies that only a company the size of Google – not even a government – could create Street View. Legend has it that open source geeks heard that as a challenge, and so we have OpenStreetMap. Caffarra’s fiery anger raises the question: at what point do the infrastructure providers become so entrenched that they could choke off an open source competitor at birth? Caffarra wants to build a digital public interest infrastructure using the gaps where Big Tech doesn’t yet have that control.
The Dutch Groenlinks MEP
Van Sparrentak thinks one way out is through public procurement; adopt goals of privacy and sustainability, and support European companies. It makes sense; as the AI Now Institute’s Amba Kak, noted, at the moment almost everything anyone does digitally has to go through the systems of at least one Big Tech company.
As Sebastiano Toffaletti, head of the secretariat of the European SME Alliance, put it, “Even if you had all the money in the world, these guys still have more data than you. If you don’t and can’t solve it, you won’t have anyone to challenge these companies.”
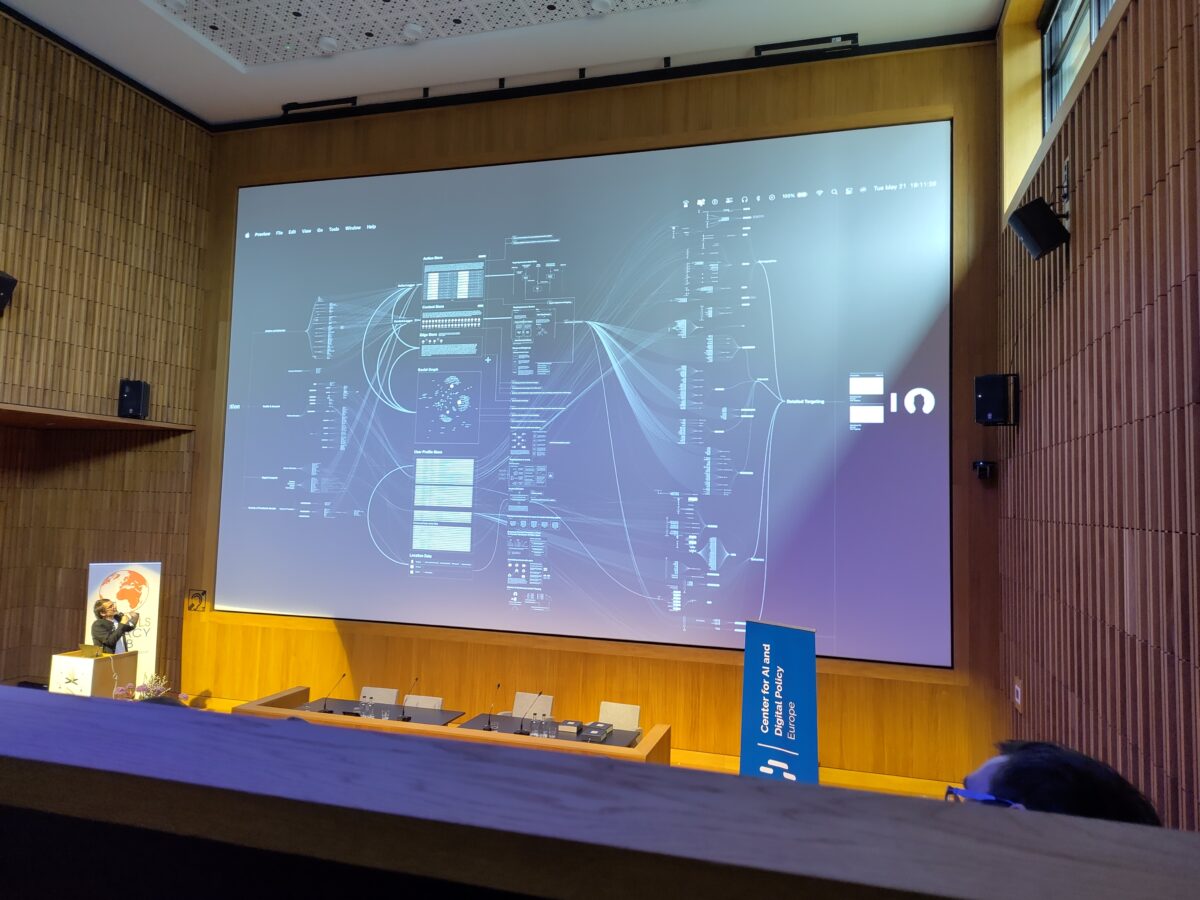
Illustrations: Vladen Joler shows Anatomy of an AI System, a map he devised with Kate Crawford of the human labor, data, and planetary resources that are extracted to make “AI”.
Wendy M. Grossman is the 2013 winner of the Enigma Award. Her Web site has an extensive archive of her books, articles, and music, and an archive of earlier columns in this series. She is a contributing editor for the Plutopia News Network podcast. Follow on Mastodon.






{kind=link}