Once upon a time, “convergence” was a buzzword. That was back in the days when audio was on stereo systems, television was on a TV, and “communications” happened on phones that weren’t computers. The word has disappeared back into its former usage pattern, but it could easily be revived to describe what’s happening to content as humans dive into using generative tools.
Said another way. Roughly this time last year, the annual technology/law/pop culture conference Gikii was awash in (generative) AI. That bubble is deflating, but in the experiments that nonetheless continue a new topic more worthy of attention is emerging: artificial content. It’s striking because what happens at this gathering, which mines all types of popular culture for cues for serious ideas, is often a good guide to what’s coming next in futurelaw.
That no one dared guess which of Zachary Cooper‘s pair of near-identicalaudio clips was AI-generated, and which human-performed was only a starting point. One had more static? Cooper’s main point: “If you can’t tell which clip is real, then you can’t decide which one gets copyright.” Right, because only human creations are eligible (although fake bands can still scam Spotify).
Cooper’s brief, wild tour of the “generative music underground” included using AI tools to create songs whose content is at odds with their genre, whole generated albums built by a human producer making thousands of tiny choices, and the new genre “gencore”, which exploits the qualities of generated sound (Cher and Autotune on steroids). Voice cloning, instrument cloning, audio production plugins, “throw in a bass and some drums”….
Ultimately, Cooper said, “The use of generative AI reveals nothing about the creative relationship to work; it destabilizes the international market by having different authorship thresholds; and there’s no means of auditing any of it.” Instead of uselessly trying to enforce different rights predicated on the use or non-use of a specific set of technologies, he said, we should tackle directly the challenges new modes of production pose to copyright. Precursor: the battles over sampling.
Soon afterwards, Michael Veale was showing us Civitai, an Idaho-based site offering open source generative AI tools, including fine-tuned models. “Civitai exists to democratize AI media creation,” the site explains. “Everything has a valid legal purpose,” Veale said, but the way capabilities can be retrained and chained together to create composites makes it hard to tell which tools, if any, should be taken down, even for creators (see also the puzzlement as Redditors try to work this out). Even environmental regulation can’t help, as one attendee suggested: unlike large language models, these smaller, fine-tuned models (as Jon Crowcroft and I surmised last year would be the future) are efficient; they can run on a phone.
Even without adding artificial content there is always an inherent conflict when digital meets an analog spectrum. This is why, Andy Phippen said, the threshold of 18 for buying alcohol and cigarettes turns into a real threshold of 25 at retail checkouts. Both software and humans fail at determining over-or-under-18, and retailers fear liability. Online age verification as promoted in the Online Safety Act will not work.
If these blurred lines strain the limits of current legal approaches, others expose gaps in the law. Andrea Matwyshyn, for example, has been studying parallels I’ve also noticed between early 20th century company towns and today’s tech behemoths’ anti-union, surveillance-happy working practices. As a result, she believes that regulatory authorities need to start considering closely the impact of data aggregation when companies merge and look for company town-like dynamics”.
Andelka Phillips parodied the overreach of app contracts by imagining the EULA attached to “ThoughtReader app”. A sample clause: “ThoughtReader may turn on its service at any time. By accepting this agreement, you are deemed to accept all monitoring of your thoughts.” Well, OK, then. (I also had a go at this here, 19 years ago.)
Emily Roach toured the history of fan fiction and the law to end up at Archive of Our Own, a “fan-created, fan-run, nonprofit, noncommercial archive for transformative fanworks, like fanfiction, fanart, fan videos, and podfic”, the idea being to ensure that the work fans pour their hearts into has a permanent home where it can’t be arbitrarily deleted by corporate owners. The rules are strict: not so much as a “buy me a coffee” tip link that could lead to a court-acceptable claim of commercial use.
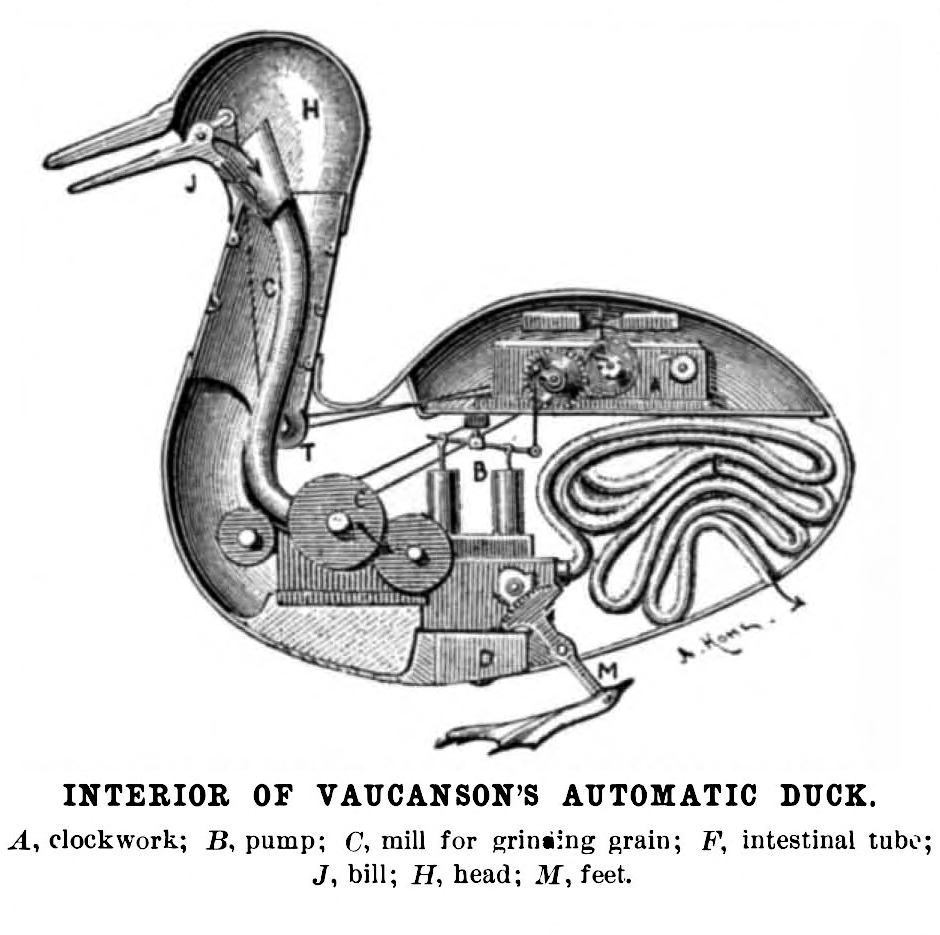
History, the science fiction writer Charles Stross has said, is the science fiction writer’s secret weapon. Also at Gikii: Miranda Mowbray unearthed the 18th century “Digesting Duck” automaton built by Jacques de Vauconson. It was a marvel that appeared to ingest grain and defecate waste and that in its day inspired much speculation about the boundaries between real and mechanical life. Like the amazing ancient Greek automata before it, it was, of course, a purely mechanical fake – it stored the grain in a small compartment and released pellets from a different compartment – but today’s humans confused into thinking that sentences mean sentience could relate.
Illustrations: One onlooker’s rendering of his (incorrect) idea of the interior of Jacques de Vaucanson’s Digesting Duck (via Wikimedia).
Wendy M. Grossman is the 2013 winner of the Enigma Award. Her Web site has an extensive archive of her books, articles, and music, and an archive of earlier columns in this series. She is a contributing editor for the Plutopia News Network podcast. Follow on Mastodon.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}